

Agentless vs. Agent-based ITAM: Which is better for your business?
Let’s take a look at some different ways IT Asset Management systems collect data. Let us begin by defining IT Asset Management (ITAM): IT Asset Management describes a set of practices that track and audit the life cycles of any purchased assets; IT related in this case, including inventory counts, as well as any contract-based expenses for licensing, support, and the like. Along with inventory, relevant expenses are documented. These often include details like the purchase price, any yearly recurring costs (licenses and/or maintenance), purchase dates, and if applicable, end of life/end of service (EOL/EOS) dates as well. Service contracts can be tracked by IT asset management tracking systems, associating the contracts with the assets they apply to. Licenses and totals in-use counts are tracked in the same manner, all ‘accounted for’ in a single central location.
By no means is an ITAM system limited to doing just these things – many do much more. A decent IT asset management system, however, should at the least be able to track these basic details about each IT assets. Quality systems will often do much, much more, tracking everything from each IP to running services to installing software and services, which are running and which are not their configurations, and most importantly, the interdependencies between all of these things!
Asset management challenges
Asset management presents different challenges to organizations of different sizes as well as different age. Smaller organizations, especially in the startup stage may have so few “assets’ that it isn’t considered necessary to ‘audit’ them officially. If an entire companies’ IT assets can fits in a single car or conference room, or if all assets are come and go with the employees (e.g. a half-dozen laptops), it may seem to many [and rightly so] that setting up a detailed tracking process for these assets might be unnecessary.
As successful companies grow however, and begin to hire more and more employees and acquire their first, second, fifth, and tenth server as well as their 50th, hundredth, etc. laptop, at some point a formal asset management process to track and inventory these assets and their replacement lifecycles begins to make good sense both practically and for the business.
Growing companies find themselves in this position regularly and must decide how to proceed once a process has been designed to reconcile the empty inventory and populate it with all of the assets the organization owns and their details. Another case where this problem is encountered is during a merger or an acquisition wherein the organization being acquire has no/poor/lost and/or a very different ITAM procedure. How can the newly acquired assets be easily reconciled and merged with your current asset data? This process can either be performed manually, or automatically, and if automatically it can be done without the use of agents, or can be approached with agents in mind.
Both the agentless approach and agent-based approach have advantages and disadvantages. Specifically, the advantages and disadvantages of an agent-based approach to asset management vs. an agentless approach (a mixed approach is a very real possibility, as well, and has advantages & disadvantages of its own as well) are as such:
Agent-less |
Agent-based |
Pros:
| Pros:
|
Cons:
| Cons:
|
Let’s examine IT Asset Management (ITAM) from a “30,000 foot” perspective. From this view, it should be noticed that though there are a variety of processes, many of which differ in detail and execution, there are in essence are only three high-level approaches to discovery for asset management tracking. No matter which specific method you end up settling on, your method will almost definitely utilize one of these three techniques underpinning it:
- Manual asset discovery / tracking
- Automated, agent-based discovery / tracking
- Automated agentless asset tracking & discovery.
What does ‘automated’ asset discovery really mean?
Automated in terms of asset discovery means what you likely think it to mean. As opposed to going down (or sending an employee down) to the server room (and/or each office) to count each and every server and connection via pen&paper, the automated processes accept a server name, IP, range of IP addresses, and/or entire blocks of addresses which can be ‘automatically’ scanned and ‘discovered’ using the login credentials you specify. All that is required is that the target machines are online in this address space that you provided, that those servers are on, and that those servers accept the discovery credentials you’ve provided.
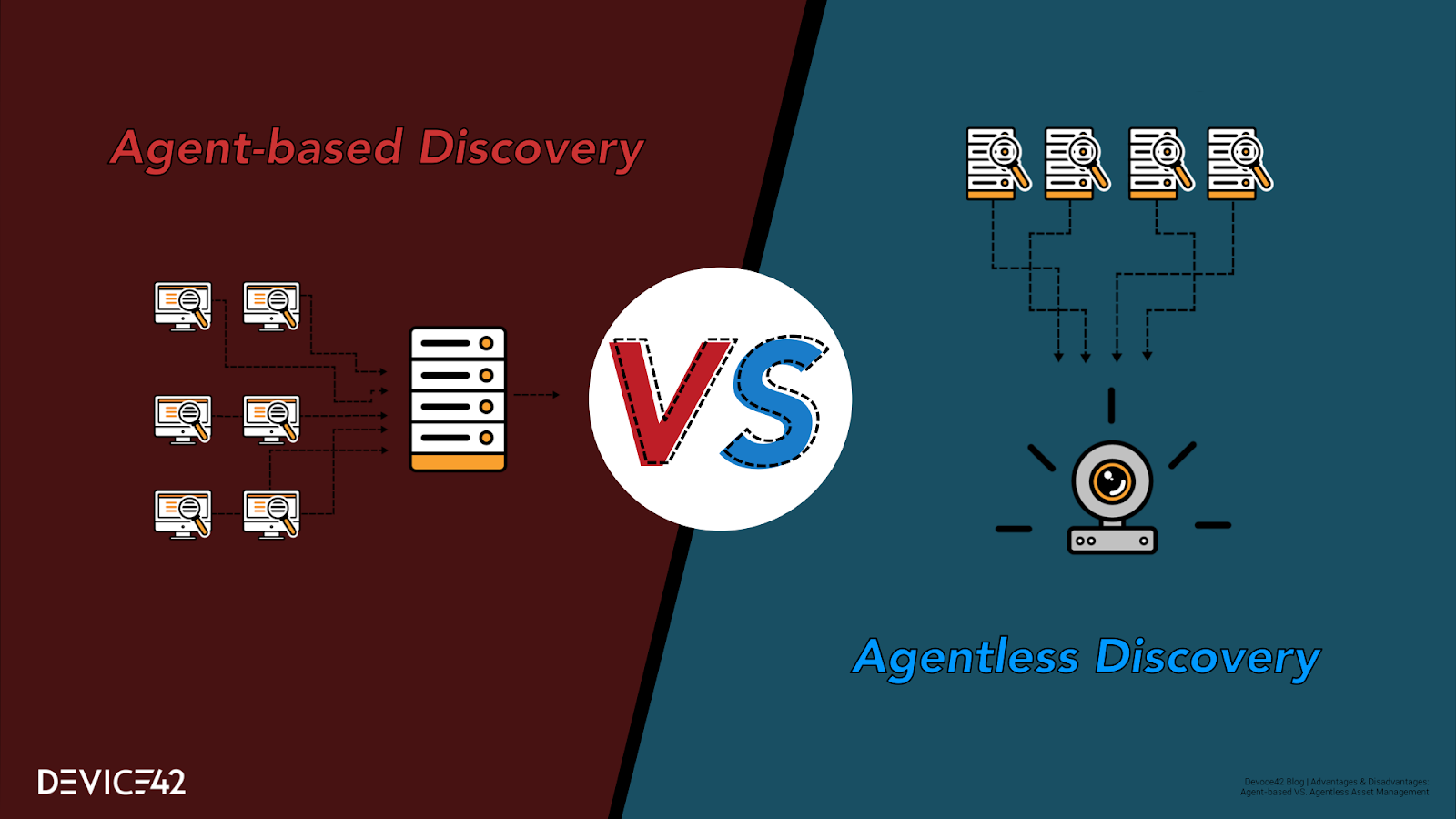
Agentless Asset Discovery
Agentless discovery reaches out to each server, attempts to ‘log on’ and or query the server using industry standard and/or manufacturer-specific protocols (depending on the specific discovery software being used and its capabilities). These can range from SNMP to SSH for ‘completely generic’ network-hardware discovery [most operating systems have at least some support SNMP as well]. More platform-specific API-based discovery technologies like WMI and WinRM for Windows and SSH for Linux/Unix can be used for discovery. Still, other methods use Netflow to map communication traffic between network devices, using information gleaned to infer what is being utilized, or packet capture which captures all traffic that traverses a network, leveraging powerful dedicated computer processors to analyzes that traffic.
All of these techniques require that the ITAM discovery software be connected to the same network as the endpoints to be discovered, and that this link remains functional. For the most part, this is in and of itself not a problem, as should the network go down, there is a good chance the services being monitored are down too, and the agentless process can resume scanning as soon as the connection is re-established. There are special cases, however, with ultra-secure networks that do not permit communication in two directions or to specific subnets — in which case an agent-based approach could be the preferred (or perhaps the only choice).
Agent-Based Discovery
Agent-based discovery places an “agent” on each discovery target. This software agent is a piece of code that runs on the target machine, and instead of being called upon remotely (such as is done for SNMP), the agent instead “calls home” to report back its findings every X (configurable; 600sec [5 min] is a common default) seconds (or minutes!) depending on the type of data to be gathered and the frequency it needs to be updated, keeping in mind that more frequent updates can begin to cause appreciable load.
One advantage of agent-based discovery often cited by vendors that use this model is that data can be gathered without an open port on the target, and even without a direct connection between the system in question and the endpoint target. The agent, being local, is able to gather data and “store” it, delivering hours, days, weeks, or even months of data in large chunks if an when a connection does become available. Other scenarios where this can make sense are for example laptops that are often out of the office checking in with an ITAM system, or security-isolated servers on their own VLANs. Data can, of course, be transported on a more regular, scheduled basis if desired, or in the most strict of cases, less often and possibly even manually via sneakernet (for extremely isolated and/or disconnected systems).
And oft-encountered “catch-22” when it comes to agent-based discovery for IT asset management tracking is the fact that to track your inventory, you must first install agents; but if you do not already have your inventory tracked, from where is an administrator supposed to produce the complete list of machines that need agents installations, and how can that admin know if they’ve gotten all instances? This doesn’t present a significant challenge in small and even well-staffed medium sized IT enterprises with IT departments that have an internal “map” fo their entire deployment in their heads. This is a very real problem, however, and is one of the main reasons an agentless, scan-based approach might be preferred.
Combination Agent & Agent-based?
As is true for many things, the best option can often be found by taking the best from all options and utilizing each in those cases that will be best served by them. One of the greatest challenges to this logical, if not idealistic approach lies in the fact that most vendors will focus their development efforts on one technology or the other and therefore either only offer only an agentless or only an agent-based solution, or in other cases might offer both but only offer support for one. Still other cases they might offer and support both, but one method is far superior for the first reason mentioned.
Should you come across a vendor that not only supports both agentless and agent-based discovery [like Device42] where both methods have the same capabilities as well [Device42!], the best choice very well might be a combination of agentless discovery and agent-based discovery for mixed use and/or mix classification networks. Still, other agents can serve a dual-purpose, also working as ‘monitoring agents’, killing two birds with one stone should you not have a monitoring system (or satisfactory system) in place.
Another reasonable approach might be performing the initial discovery via agentless, leveraging that data for the list of endpoints to install agents; this technique uses the strengths of both to initially discover and then proceeds to deploy agents to manage and track assets going forward. This eliminates the requirement to have a previously-existing and functional asset-management tracking system in place.
Choose a vendor who offers a platform that meets your specific needs first
Both systems have advantages. If you must choose a vendor that only offers one or the other, take into consideration whether or not you:
- Are OK with agents installed on every machine
- Already possess an accurate list of machines to install those agents on
- Are comfortable performing the up-front work installing those agents requires
- Have a network that requires the use of agents to reach a significant number of secure machines you are certain you want to track
If you are comfortable with all of the above, ensure you have chosen a vendor who has a solid record of standing behind customers and ensuring customer satisfaction. Make the capabilities of a given platform are known, and ensure that any vendor that is seriously considered doesn’t take your ITAM data hostage; It is important that you are allowed to export data discovered about your IT environment.
A vendor that supports agentless as it’s *primary” discovery technology, or alternatively, an agentless-only vendor might be the ideal choice for you if your organization possesses a fairly large IT deployment, and/or does not have much any idea how many IT assets need to be discovered.
Don’t forget to look at the details around *what* is discovered, either!
Regardless of the discovery approach you choose to meet your needs, ensure that you evaluate the details around *what* is discovered. As, if not more important than the discovery method is the details that the chosen method uncovers! What good is an agent-less discovery approach that though easier, cannot tell you the information you need to know about each asset?
Compare the offerings (and the discovery results!) from multiple vendors against each other. Rushing through a comparison or product evaluation could lead to the unfortunate purchase of an “alternative” product that wasn’t an alternative at all..! In Latin, the saying goes Caveat emptor — which roughly translates to buyer beware!
Don’t take any vendor simply at their word when it comes to such an important (and relatively) large purchase that will likely affect the direction of your business for many years to come! When it comes to good ITAM, don’t rush or ‘settle’, especially for any vendor that won’t let you try their solution before you buy. There are many solid and mature ITAM asset management tracking product offerings available, however, there are products available that are much more marketing than functionality. Ensure you can TRY a product this significant for yourself — against your actual environment if you desire — BEFORE you commit to buy!
It’s not a great idea to trust anyone who won’t let you at least take an ITAM software suite for a test-drive… What are they hiding!?
For further insights into CMDB, Cloud Migration, DCIM, ITAM, and Compliance best practices, explore www.device42.com.


