

As business priorities change, specially sometimes in middle of projects, or people move within or outside organizations, or applications get replaced by new technologies – enterprises are left with servers, containers, or cloud services that are just sitting there and collecting dust, albeit virtual in some cases.
In this post, we will attempt to help you identify, and eliminate these zombie workloads. In the first part of this blog, we’ll provide you with direct resources/commands that you can use with AWS, Azure or Google compute workloads. After that, we get into some dashboards, and DOQL that you can run within Device42 to do the same.
Different Types of Zombie IT Workloads

Here are some examples of zombie resources in your IT infrastructure:
| On-Prem: |
|---|
| Servers in the datacenter that are not even powered-on |
| Virtual machines in private cloud that are not powered on |
| Physical or virtual machines that are powered on, but never configured or with no software installed |
| Machines with software installed but no running services |
| Machines with everything running, but nothing else connecting to it – as in machine serving no real purpose |
| Machines that are over-sized, i.e. – more than required CPU, memory and disk resources |
| Cloud (private or public): |
|---|
| Cloud VMs that are not powered-on |
| Unattached Persistent disks or EBS volumes |
| S3 or object-storage files that haven’t been accessed in years |
| Stale snapshots |
| Under-utilized resources |
| Stale data in PaaS, DB resources with any TTL |
| Logs that no-one is ever going to look at |
| Load balancers where targets are turned off |
| Unattached IP resources |
Tools required to identify Zombies
- Access to CLI for cloud (and on-prem) resources.
- Checklist, possible in some spreadsheets based on some of the ideas provided here.
- Optional, but ideal: CMDB with trustable data
- Optional: For right sizing workloads – access to data from monitoring tools, or tools that gather resource utilization data can help.

Cloud: Steps and Recommendations
While hyperscalers have tools like cost explorer that can help with this quite a bit, we are providing some example commands below to help identify:
Identify powered-off virtual machines:
AWS:
aws ec2 describe-instances --filters Name=instance-state-name,Values=stoppedAZURE:
az vm list -d --query '[?powerState == `VM stopped` || powerState == `VM deallocated`]'GCP:
gcloud compute instances list --filter="status:TERMINATED OR SUSPENDED"Persistent disks or EBS volumes that are not associated with any resource:
For Google Cloud, you can use the following command:
gcloud compute disks list --filter="-users:*"For AWS:
aws ec2 describe-volumes --filters Name=status,Values=available,errorFor Azure:
az disk list --query '[?managedBy==`null`]'Identify log retention policies – are you keeping logs forever?
Resources to identify logs:
AWS:
AZURE:
https://learn.microsoft.com/en-us/azure/azure-monitor/logs/data-retention-archive
GCP:
https://cloud.google.com/logging/docs/buckets#custom-retention
Object storage – bucket policies and rotation into cold storage. It is generally a good idea to identify stake holders.
AWS:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html
https://docs.aws.amazon.com/AmazonS3/latest/userguide/analytics-storage-class.html
AZURE:
https://learn.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-overview
https://learn.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-policy-configure
GCP:
Stale data in Firestore/CloudSpanner
Best way is to SET the TTL policies
https://cloud.google.com/datastore/docs/ttl#create_ttl_policy
https://cloud.google.com/spanner/docs/ttl/working-with-ttl
What cloud resources are associated with what stake holders? This consistent governance and can save a ton on money on an ongoing basis. Snapshots, specially older snapshots that can be now deleted.
AWS:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/object-lifecycle-mgmt.html
https://docs.aws.amazon.com/AmazonS3/latest/userguide/analytics-storage-class.html
AZURE:
https://learn.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-overview
https://learn.microsoft.com/en-us/azure/storage/blobs/lifecycle-management-policy-configure
Snapshots, specially older snapshots that can be now deleted.
AWS:
aws ec2 describe-snapshots --owner-ids $AWS-ACCOUNT-ID --filters Name=status,Values=completed --query 'Snapshots[?StartTime <= `2022-09-23`]'AZURE:
az snapshot list --query '[?timeCreated <= `2022-09-23`]'GCP:
gcloud compute snapshots list --filter="creationTimestamp<'2022-01-01'"Unattached IP resources:
AWS:
# network interfaces
aws ec2 describe-network-interfaces --filters Name=status,Values=available
# Elastic IPs
aws ec2 describe-addresses --query 'Addresses[?AssociationId==null]'AZURE:
# network interfaces
az network nic list --query "[?(virtualMachine==null)]"
# public IPs
az network public-ip list --query "[?(ipConfiguration==null)]"GCP:
gcloud compute addresses list --filter="status:RESERVED AND -network:*"What data you get from Device42
Now onto getting this data directly from Device42 CMDB: We have created the following dashboard within D42 to help with finding zombie workloads in your cloud infrastructure.
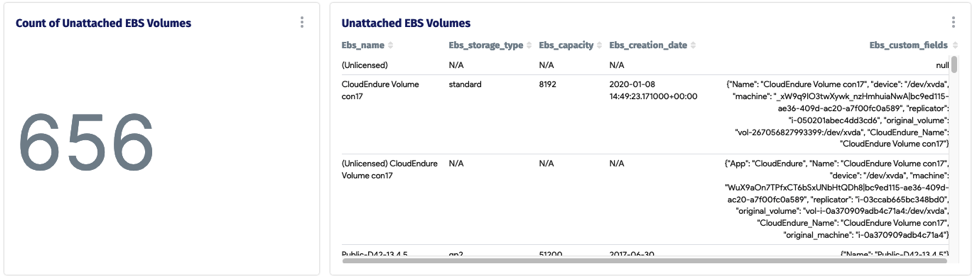

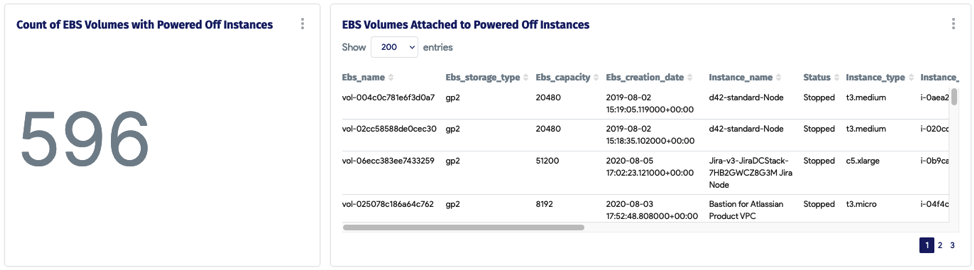
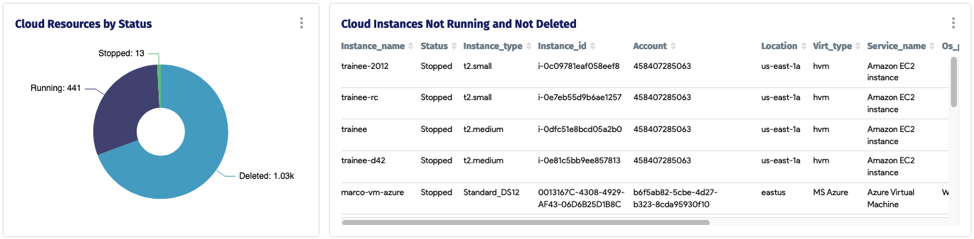
On-prem: Steps, and recommendations
- Audit your racks – what is not powered on.
- Run an analysis on your private cloud/hypervisors. What VMs are not powered on.
- Run a report within Device42 for machines with software installed.
- Similarly what machines have no running services? Identify using your CMDB. You can also do this by checking utilization either in D42 or your monitoring software – what machines have no CPU or memory usage?
- For right sizing – similar as above, but what machines are running underutilized and you can save CPU and memory?
You can take it one step further with our AI/ML algorithm published here.
And here is a DOQL that you can run in D42.
Conclusion
Longer term it is a governance problem. You need a process, and process needs to evolve as IT changes. Having a turn-key CMDB tools that can surface such reports for you on a regular basis is ideal.
