ITSM Best Practices: Starting with Strong Foundations
It is commonly observed that IT teams, while skilled in technical management, struggle to effectively bridge the gap between their capabilities and business priorities. Capability gaps can relate to technical skills, understanding the maturity of current IT service management (ITSM) processes, or crafting a clear path forward.
IT leaders often give inconsistent answers when asked, “what level of service management capability have you achieved?” or “how do you know your process improvement initiatives are working?” More concerning is the fact that these answers rarely align with what these leaders’ business stakeholders think.
In this article, we discuss ITSM best practices, how and when you should implement them, and, most importantly, the steps to measure the maturity of your ITSM practices.
Summary of key ITSM best practices
When you’re looking to improve your IT service management capabilities, there can be a number of processes and practices that need attention. Where do you start? What should you prioritize? How do you make sure improvements stick?
In the sections to follow, we discuss practical approaches to implement powerful improvements in your organization.
| Best practice | Description |
|---|---|
| Level up your IT processes | Focus on improving the maturity of core ITSM processes like incident, problem, and change management. |
| Avoid the quick-fix cycle | Avoid temporary solutions by balancing incident resolution with sustainable problem management. |
| Manage change with the 4 Rs model | Use a risk-based approach to manage changes by focusing on reason, risk, resources, and responsibility. |
| Transform information silos | Convert isolated knowledge into shared, accessible resources to improve collaboration and efficiency. |
Level up your IT processes
Process improvement practices should follow a clear, step-by-step approach based on structured assessment frameworks. Organizations typically achieve the best results by first focusing on core ITSM processes with established workflows before expanding improvement efforts to other areas. Marrone et al.’s 2014 cross-national studies show that incident management, problem management, and change management process refinements—either collectively or as standalone efforts—offer the highest return on investment.
Each process improvement should balance measurable targets (like cost savings) with its core objectives, whether that is improving IT productivity, service quality, or change accuracy. For instance, incident management should target quick resolution and service quality maintenance, problem management should focus on reducing unplanned labour and minimizing impact, and change management should maintain protected services while ensuring efficiency.

Critical success factors by process

A division of Freshworks, which offers a comprehensive suite of ITSM solutions.
Fastest time to value with easy implementation and agentless asset discovery
Comprehensive hardware and software inventory management

Broadest discovery from legacy technology to the latest cloud and containers
Structured assessment methodologies, such as the KISMET model’s process capability assessment framework, offer practical guidance on implementing process improvement practices. The framework’s capability levels represent a sophisticated maturity model that describes how well an organization currently executes its ITSM processes and highlights the scope for improvement.
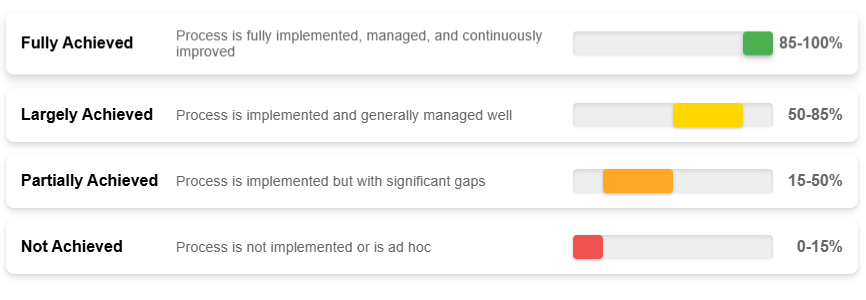
Measuring process maturity with capability levels
The implementation approach should be cross-functional, involving key organizational units, and it must be championed by identified ITSM leaders who can act as catalysts for change. A typical implementation cycle would begin with evaluating the current state of identified processes using KISMET’s assessment framework. The evaluation checks are to determine whether:
- Everyone knows what they’re supposed to do
- The steps of implementation are documented and followed
- Someone is measuring the results
- Someone’s in charge of keeping things on track
Each evaluated process should be rated on a scale from “Not Achieved” to “Fully Achieved” based on specific maturity dimensions. Moving between capability levels can differ for different organizations, but in all cases, it requires adopting a systematic approach, as outlined in the table below.
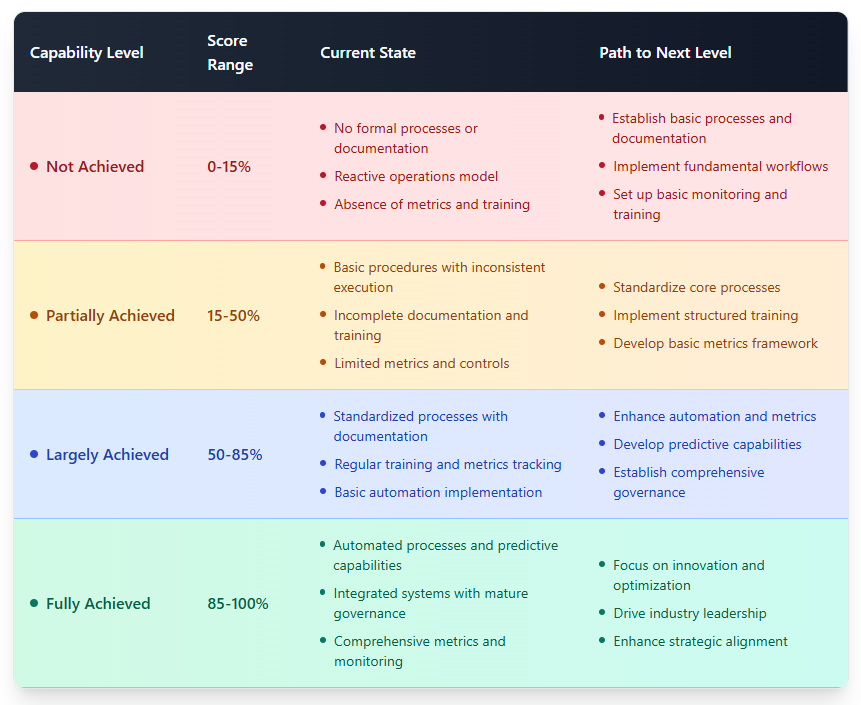
Evaluating IT processes with capability scores

It is important to compare the pace of implementation against the overall change capacity, i.e., how well your organization can absorb new changes and support the transition. In the end, you want your operations to run smoothly, though how excellence is measured may vary significantly among organizations (or even between different verticals of a single enterprise).
Avoid the quick-fix cycle
Faster resolutions mean happy customers and impressive metrics. However, this approach creates a “shifting the burden” pattern where quick workarounds become the default response and sustainable solutions are pushed aside.
To avoid falling into this counterproductive approach, consider balancing the pace of resolving incidents with adequate time invested in root cause analysis.
A fundamental shift in how you view problem management is also a must. Rather than treating it as an extension of incident management, problem teams need dedicated space for analysis and should be protected from being pulled into incident handling, even during major incidents. A segregated approach ensures that while incidents are being resolved, a parallel track focuses on root cause analysis without the pressure of immediate resolution metrics.

A “shifting the burden” pattern in ITSM
For deeper analysis, there are numerous theoretical frameworks that can help with systematic problem investigation. For example, the Cynefin Framework can be modeled to categorize known errors based on their nature (simple, complicated, complex, or chaotic) and guide the response strategy. Another is using the observe, orient, decide, act (OODA) loop as a dynamic decision-making model to help adapt to changing circumstances during problem investigation.
Sure, these approaches require more upfront time and effort than quick fixes, but they create a stronger service management foundation, gradually reducing the reliance on quick workarounds.
Manage change with the 4 Rs model
Controlling every change the same way is neither practical nor necessary. Consider a routine database update versus a full system migration: These changes have fundamentally different risk profiles, yet an organization may subject both to the same rigorous (or otherwise) approval process. When you apply the same heavy controls to both routine and complex changes, there are two aspects to consider:
- Resources get stretched and teams have less time to properly assess the changes that truly need attention.
- Teams tend to start labelling everything as an “emergency” to bypass the process, defeating the purpose of a priority matrix entirely.
A better approach is to match controls with actual risks. Consider adopting a risk profiling mechanism that helps you achieve a more nuanced view of change risk and apply appropriate controls without over- or under-controlling changes.
Industry standards recommend extensive change evaluation criteria, for instance, using all 7 Rs of Change simultaneously to assess each proposed change. But for standard and low-risk changes, a more conservative and practical approach is to start with only four key elements:
- Reason: What business value drives this change?
- Risk: What could go wrong, and how severe would it be?
- Resources: Who and what do we need to implement this?
- Responsibility: Who owns the outcome?
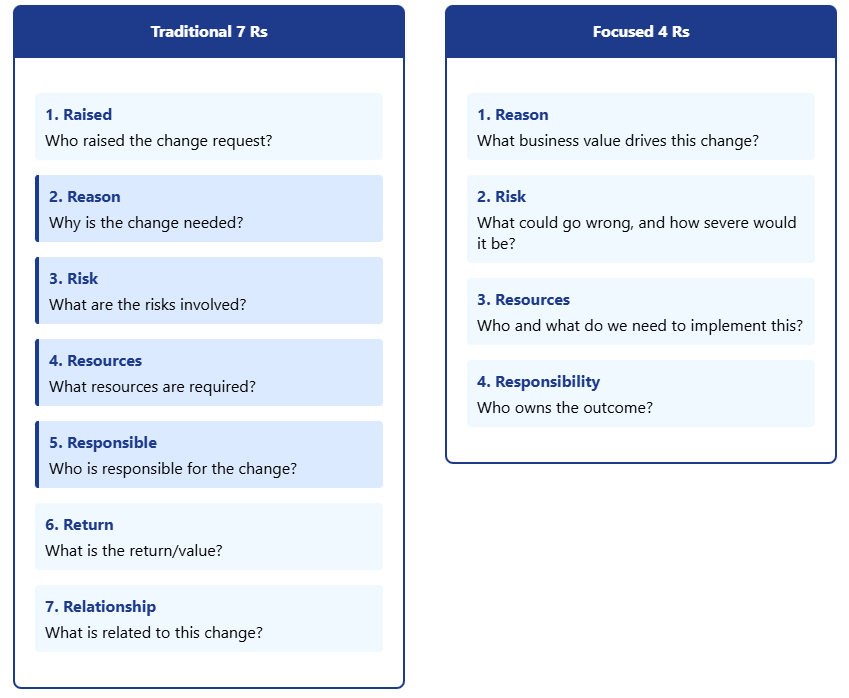
Adopting the conservative Rs approach over traditional Rs
Starting with these 4 Rs addresses the essential questions that determine a change’s viability and impact. That said, it’s not that the other elements don’t add value. While the 4 Rs model works well for routine changes, more complex changes require a more comprehensive assessment to effectively manage risk. In such cases, consider technical complexity, business impact, resource requirements, timing constraints, and dependency scope as key indicators to weigh the overall severity of the change.
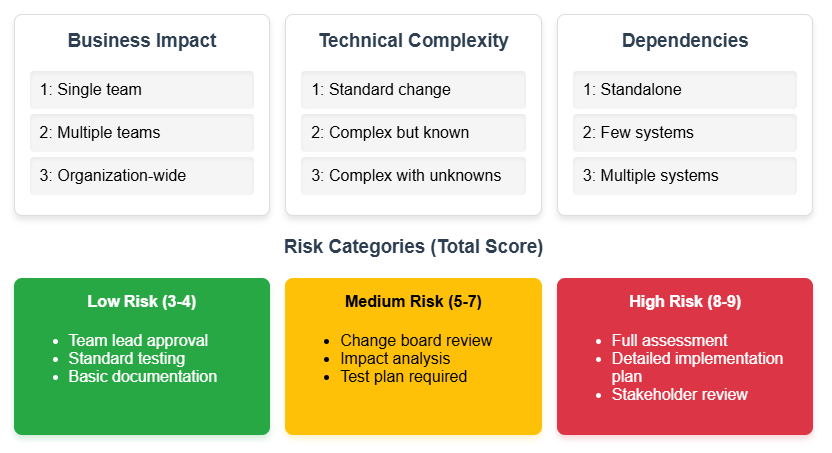
Three-dimensional change risk profiling framework
When evaluating changes using this model, particularly when weighing the “risk” and “resources” elements, consider the implementation aspect as well. Note that it is the organization’s release management practice that provides guidance around implementation. To relate this better, consider the subtle yet important distinction between the release and change practices:
- Change enablement: “Should we do this?”
- Release management: “How do we do this safely?”
If your organization doesn’t naturally separate these functions, you need to clearly map out responsibilities. A clear separation between change enablement and release management doesn’t necessarily mean these teams should work in isolation; rather, it helps create better accountability for both evaluation and implementation outcomes.
Convert information silos to shared knowledge
The ITIL 4 Service Value System (SVS) views information as a dynamic asset that flows through the entire organization and connects every component of service delivery. When the service desk resolves an incident, when developers create new features, or when operations teams manage changes, learning should flow both ways. This essentially creates a continuous cycle, where insights become both an input to and output of service management activities.
The data-information-knowledge-wisdom (DIKW) model also shows us how this works in practice. Data becomes information when given context, information becomes knowledge when applied, and knowledge becomes wisdom through experience and understanding.
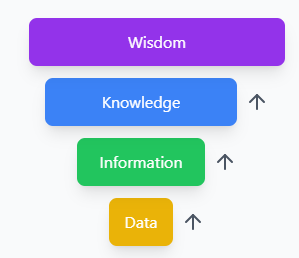
Increasing value and insight with the DIKW model hierarchy
Your knowledge management practice must connect solutions, processes, and technical context for the purpose of efficient referenceability. If you are unsure how the practice fares in your organization, assess how your team solves problems today and map how information currently moves through your organization. Notice how often the same questions come up, how frequently similar issues need solving, and how much time gets spent searching for information someone else already has.
A further step is to assess knowledge potency by examining the quality of decisions when teams have better access to information. Track concrete examples where shared insights led to different (and better) choices than before.
To build a knowledge management practice that aligns with the SVS, focus on these three elements:
- Context: Solutions and documentation must connect directly to the components they affect. A troubleshooting guide is most valuable when viewed alongside the affected system.
- Accuracy: Information must stay up to date as systems and processes evolve. Process documentation matters most when it reflects current configurations.
- Accessibility: Teams need relevant information when and where they make decisions. Historical context helps most when tied to specific changes and their impacts.
Tools like Device42 can strengthen your knowledge management foundation and provide accurate visibility of your infrastructure and its interconnections through automated discovery, comprehensive asset management, and dependency mapping. That said, a tool will have the most impact when the approach is right. Pick one recurring incident or problem that impacts your teams frequently. Document how you investigate and resolve it, create different versions of the documentation for different user groups—like first-line support or specialists—and observe how teams use these resources. You’ll start to see patterns emerge, showing where shared expertise creates the most value for your organization.
It is important to note that the ultimate purpose of this approach is not to collect more data but to help people easily find and apply insights in their daily work. Start with clear categories, maybe organized by service, common issues, or team. Use consistent knowledge base templates so people know where to find what they need, and make sure they’re written in language that matches how your teams actually talk about problems.
Last thoughts
Most IT organizations today are stressed by trying to balance their core responsibilities with a growing list of technology demands. Achieving higher process maturity in this environment can feel overwhelming, especially when dealing with abstract improvements that aren’t immediately visible. Device42 gives you that essential foundation of visibility, so you can stop firefighting and start focusing on what matters.
Whether you’re starting your transformation journey or looking to reach the next level of service maturity, Device42 can be your partner and offer you a clear view of the environment that you need.
Learn more about why and how many leading organizations and ITSM providers choose Device42 for its comprehensive discovery and dependency mapping capabilities to supercharge their ITSM platforms.